Kafka
기본 BXI설정은 온라인 인스턴스에서 거래 및 로깅 처리를 모두 담당한다.
로깅 인스턴스 및 Kafka를 이용해 해당 역할을 분리할 수 있는데, 이 때 거래 처리 스레드와 로깅 스레드를 분리할 수 있어 가용성을 높일 수 있다.아키텍처
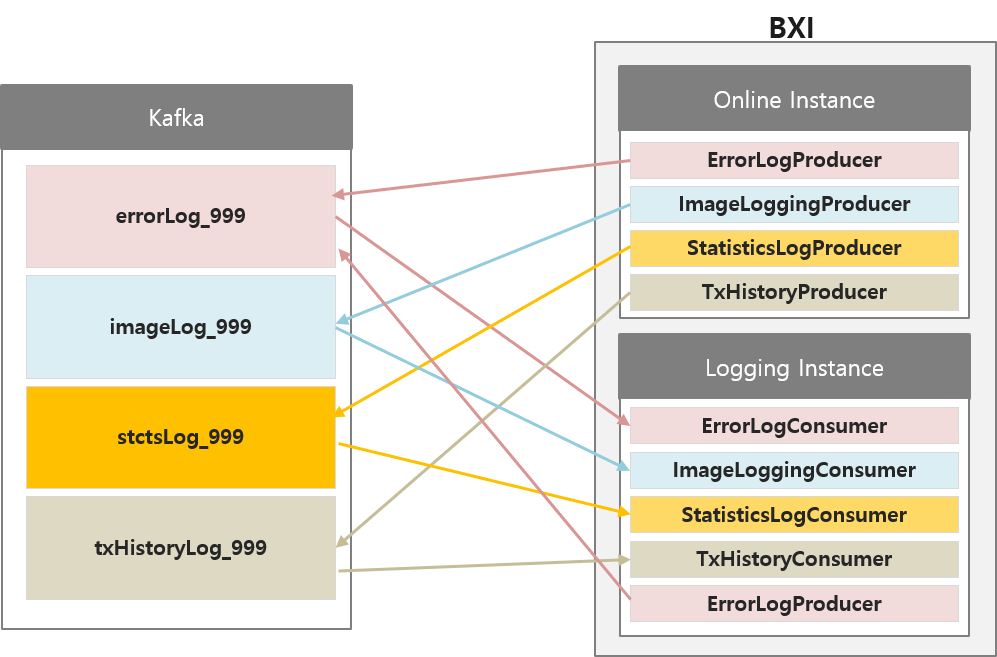
정상 설정된 카프카 서버는 용도별로 토픽이 분리되는데,
이 때 모든 토픽명은 로그명에 테넌트ID가 추가된 형태이다.
EX) errorLog_999: errorLog + _ + 테넌트ID
BXI엔진에서 온라인 인스턴스의 Producer는 각각의 토픽에 인입할 레코드를 생성해 카프카 서버에 보내고, 로깅 인스턴스의 Consumer는 각각의 토픽에서 레코드를 가져와 DB에 Insert하는 등의 실제 로깅을 수행한다.
이 때 각 토픽에 대한 Producer와 Consumer는 별도의 스레드로 작동하는데, Consumer 스레드는 해당하는 토픽의 파티션 갯수만큼 생성되며, Producer는 그보다는 적게 생성된다.(파티션 수/5)
로깅 인스턴스는 거래 처리는 하지 않으나 에러가 발생할 수 있으므로, 다른 로그와는 달리 ErrorLogProducer가 추가로 존재한다.
설정
이를 위해 필요한 설정 작업은 다음과 같다.
1. Kafka서버 설정
엔진 installer의 etc/kafka.tgz를 압축 해제하여 kafka를 사용할 수 있다.
- 물리서버가 1대인 경우
- 물리서버가 3대인 경우
1) ZooKeeper 설정
# zookeeper 데이터 경로 설정
dataDir=/tmp/zookeeper
# zookeeper 리슨 포트 설정
clientPort=2181
2) ZooKeeper실행
bin/zookeeper-server-start.sh config/zookeeper.properties
3) Kafka설정
# Kafka 리스너 설정
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://localhost:9092
# Kafka 로그 디렉터리 설정
log.dirs=/tmp/kafka-logs
# zookeeper 리스너 주소 입력
zookeeper.connect=localhost:2181
4) Kafka실행
bin/kafka-server-start.sh config/server.properties
4) 토픽 설정
카프카를 사용할 엔진마다 토픽을 5개씩 생성한다.
zookeeper의 ip, port 및 테넌트ID를 변경하여 bin/kafka-topics.sh를 아래와 같이 실행한다.
kafka를 1대만 사용하므로 replication-factor 는 1로 설정한다.
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic errorLog_${TENANT_ID} --replication-factor 1 --partitions 5
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic imageLog_${TENANT_ID} --replication-factor 1--partitions 40
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic stctsLog_${TENANT_ID} --replication-factor 1 --partitions 5
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic txHistoryLog_${TENANT_ID} --replication-factor 1 --partitions 20
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic instanceMonitoringLog_${TENANT_ID} --replication-factor 1 --partitions 10
각각의 서버에 모두 kafka를 설치해 하단 설정을 모두 진행해야 한다.
1) ZooKeeper 설정
# zookeeper 데이터 경로 설정
dataDir=/tmp/zookeeper
# zookeeper 리슨 포트 설정
clientPort=2181
initLimit=5
syncLimit=2
# Zookeeper 2888은 동기화를 위한 포트, 3888은 클러스터 구성 시, leader를 선출하기 위한 포트
server.1=서버1의IP:2888:3888
server.2=서버2의IP:2888:3888
server.3=서버3의IP:2888:3888
2) ZooKeeper실행
각각의 서버에서 모두 실행한다.
bin/zookeeper-server-start.sh config/zookeeper.properties
3) Kafka설정
# 카프카 서버의 고유 ID. 반드시 카프카 서버마다 달라야 한다.
broker.id=1
# Kafka 리스너 설정
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://localhost:9092
# Kafka 로그 디렉터리 설정
log.dirs=/tmp/kafka-logs
# zookeeper 리스너 주소 입력
zookeeper.connect=서버1의IP:2181,서버2의IP:2181,서버3의IP:2181
4) Kafka실행
kafka는 각 서버에서 모두 실행하고, 토픽 생성 스크립트는 하나의 서버에서만 실행하면 된다.
bin/kafka-server-start.sh config/server.properties
5) 토픽 설정
카프카를 사용할 엔진마다 토픽을 5개씩 생성한다.
zookeeper의 ip, port 및 테넌트ID를 변경하여 bin/kafka-topics.sh를 아래와 같이 실행한다.
kafka를 3대 기동하므로 replication-factor는 2 또는 3을 설정한다.
bin/kafka-topics.sh --create --zookeeper 서버1의IP:2181,서버2의IP:2181,서버3의IP:2181 --topic errorLog_${TENANT_ID} --replication-factor 3 --partitions 5
bin/kafka-topics.sh --create --zookeeper 서버1의IP:2181,서버2의IP:2181,서버3의IP:2181 --topic imageLog_${TENANT_ID} --replication-factor 3--partitions 40
bin/kafka-topics.sh --create --zookeeper 서버1의IP:2181,서버2의IP:2181,서버3의IP:2181 --topic stctsLog_${TENANT_ID} --replication-factor 3 --partitions 5
bin/kafka-topics.sh --create --zookeeper 서버1의IP:2181,서버2의IP:2181,서버3의IP:2181 --topic txHistoryLog_${TENANT_ID} --replication-factor 3 --partitions 20
bin/kafka-topics.sh --create --zookeeper 서버1의IP:2181,서버2의IP:2181,서버3의IP:2181 --topic instanceMonitoringLog_${TENANT_ID} --replication-factor 3 --partitions 10
2. BXI설정 변경
로깅 인스턴스 추가 후, 로컬로깅으로 되어있는 기본 설정을 리모트로깅으로 변경한다. 자세한 설정방법은 로그관리를 참조한다.